non-reasoning LLMs suck at quoridor
I’ve been playing with AIs quite a bit at work but last week I was off and I didn’t want to stop playing, so I made LLMs face each other in a game of Quoridor. I’ll share in this post the interesting insights I got (slight spoiler in the title) as well as some implementation details I found interesting. If you just want the code, check out the repo in Python.
As a note, I tested OpenAI models as well as Claude. Since I’m relying on the tool calls API, I couldn’t test Gemini 2.0 Flash Thinking (yet, once it’s fully released I will) nor DeepSeek R1 (other ones I just didn’t want to).
If you just want the results and already know what Quoridor is, skip to the results below, otherwise buckle in.
wtf is quoridor
I had never heard of Quoridor until a brainstorming session with Claude where I was prompting for fun and simple games to implement for the “LLMs play competitive matches” project to showcase their reasoning ability. It suggested this simple little weird game to me and it seemed like a fun fit.

Quoridor is a game played on a 9x9 board, where each player controls a single pawn. The game starts with each player in opposing sides of the board, in the center column. The objective is to be the first to reach the opposite side of the board.
To achieve this, you’re allowed to make one of two types of moves each turn, alternating turns with your opponent:
- move your piece one square orthogonally (up, down, left, right)
- place a 2-width wall between squares somewhere in the board, blocking movement between them
Each player starts the game with 10 walls they can place during the match, and they need to balance advancing towards their objective while hindering the opponent (and potentially using walls to protect your own path).
implementing quoridor
Quoridor seemed like an attractive choice to me because it appeared simple enough to implement while still providing LLMs a good opportunity to understand what’s happening and to plan strategically. While it was indeed simple, when implementing I was pleasantly surprised about needing to think carefulle about some details.
who owns the edges of a square?
The main reason Quoridor seemed simple is because it’s played in a square grid, which is usually pretty trivial to implement without a second thought: you just throw an NxM array at it and call it a day.
However, an interesting thing about walls (or edges) that I’ve never realized until implementing
them is that they’re a shared entity. Since walls block movement bidirectionally, if you place a
wall in the right edge of the square on Pos(row=2, col=3), you also placed a wall in the left edge
of the square on Pos(row=2, col=4).
Still, it’s straightforward. In my implementation, each square “owns” the walls in the top and right
edges of itself. This means that if you request an operation on the bottom edge of the square (row, col), the code interprets it as an operation on the top edge of the square (row - 1, col) instead, always storing and accessing this information uniquely.
So, ultimately, what I did here was to create the aforementioned array and, for each square, the only information stored is a flag indicating whether or not there is a wall above/to the right of it. This abstracts away the “canonical” edges of squares behind the API, so that agents can still want to place a wall in the bottom edge of a cell directly, with the code referencing the correct place internally.
Player position itself is way more easily stored separately as coordinates themselves, together with how many walls left each player has. This results in the following data structure for the game:
class GameState:
players: tuple[Player, Player]
edges: Edges
class Player:
pos: Pos
wall_balance: int
class Pos:
row: int
col: intexposing actions to agents
Agents can either move or place walls, and this functionality needs to be exposed to them somehow. I
did this through the following APIs, using a Dir enumeration for orthogonal directions:
move(direction: Dir), which is pretty self explanatory besides the fact that they can’t move out of bounds, into another player, or through a wall;wall_place(square: Pos, edge: Dir, extends: Dir)which places a 2-width wall starting on theedgeofsquare, and extending in the direction ofextends, as illustrated in the image below.
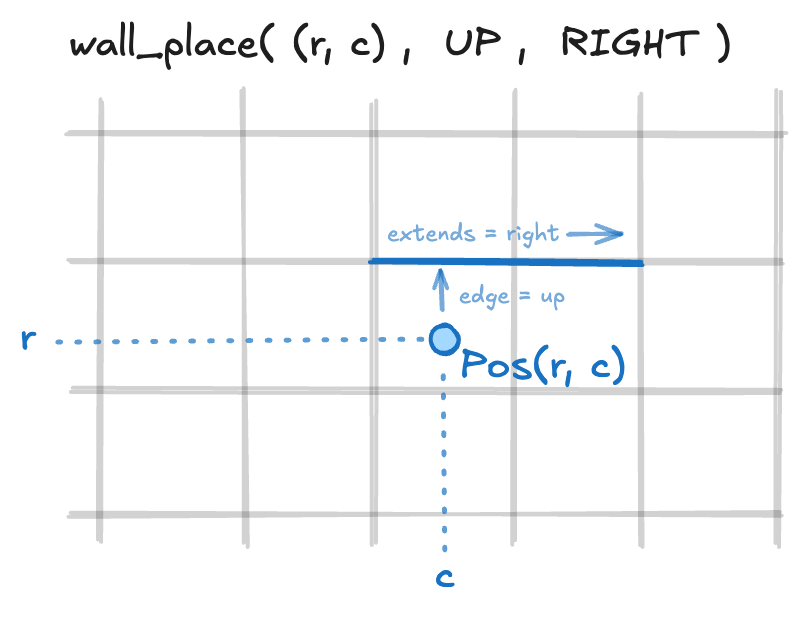
I went back and forth on the ideal definition of wall_place, and initially thought of two
different extremes:
wall_place(square1: Pos, square2: Pos, edge: Dir), needing to rely on the agent to get the two squares “right” in terms of adjacency and adherence to the direction (if the edge isUPandsquare1andsquare2are vertically adjacent it’s still invalid), implying a bit more of internal logic verifying arguments, or;wall_place(start_square: Pos, edge: Dir), which omits theextendsdirection with the implication that it’s always positive: meaning that for vertical walls it would extend to the right of the original position, and for vertical walls it would extend upwards. This would make it the hardest for the agent to make an invalid call and minimize how much we’d need to check interally, which was really attractive.
However, although I obviously liked the second approach better aesthetically, I ultimately decided
that the implied extends direction was harmful and I’d rather be explicit about the full placement
of the wall. Honestly, I just generally prefer explicit interfaces whenever possible, and I’m still
unsure if there was a real need for one here.
handling player errors with strings
There is a class of errors which are just “player errors” and not “implementation errors”, and I wanted to handle these specially for this project.
For instance, imagine an agent deciding to place a wall that’s overlapping with another one. Since the whole point of agents are that they’re agentic, instead of throwing exceptions in the program, I wanted to return LLM-readable errors explaining why the move is invalid and let them try again and see how they adapted.
Which brings me into…
agent setup
This part is relatively straightforward, but there are a few notes on how I adapted my approach based on partial results from the first few tests as well as how I wanted to save money on context length.
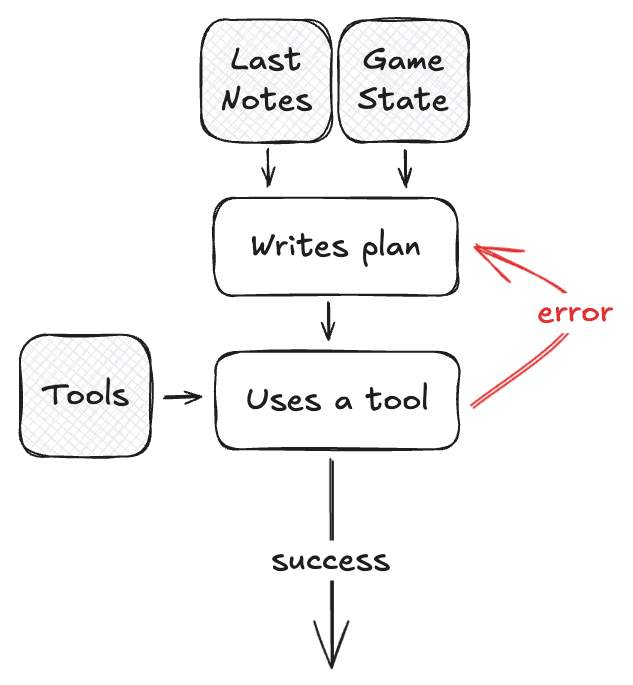
There’s obviously a system prompt that attempts to explain the rules and what is going on for each agent. Since I’m a penny pincher, instead of giving the full game history for each agent on each turn, they only get two pieces of information:
- the current state of the game (where walls are placed, where each pawn is, how many walls each player has left to place), and
- the plan that the agent wrote up in the previous turn, including anything it decided was worth remembering,
besides some helpful reminders to help them out.
Based on this prompt, the agent:
- writes a new plan/notes of the current situation, which serves both as a small reasoning (for non-reasoning models) and which will be passed to the agent the next turn,
- makes a function call to one of the two functions above.
Part of the challenge here as well is either for the agents to be really good at improvising every time, or being very smart about explicitly deciding what they want to remember/keep track off by the next turn. Since they do get the full state of the game and the optimal strategy is Markovian, this shouldn’t be a problem, and it was mostly interesting to see how different models leveraged this fact and attempted to “tell their future versions” what do to.
A very fun side-experiment to run would be to have a smart model control the game only every ~5 turns, and in between it relies on much simpler models that have access to instructions from it to play the game.
handling errors
As hinted at previously, I make tool calls return simple LLM-understandable explanations in the case of an invalid move. This turned out to be very important as non-reasoning models do tend to make invalid moves quite a bit.
While initially I just returned the tool call error and prompted for another move (without explicit replanning), this ended up resulting in basically random function calls and bad follow ups in the next turns.
To help with these issues, after adding the tool error to the message history, I looped back to prompting it to rewrite the plan/notes, which allowed it to better understand what went wrong and (1) save better notes for the next turn and (2) make a more sensible move.
board representation
When passing the “game state” to the LLMs I included basic information like player positions, balances, reminders of where each player should be trying to reach, but I needed to include information about walls. Since part of the plan was seeing how different LLMs struggled (or not) processing information, I passed them the same ASCII representation I was using myself to look at the game.
For example, the representation below, as well as a guide on how to interpret it (though I expect should be intuitive for humans).
+ + + + + + + + + +
8
+ + + + + + + + + +
7
+ + + + + + + + + +
6
+ +---+---+---+---+---+---+ + +
5 | 0
+ + + + + + + + + +
4 |
+ + + + + + + + + +
3 1
+ + + + + + + + + +
2
+ + +---+---+---+---+ + + +
1
+ + + + + + + + + +
0
+ + + + + + + + + +
0 1 2 3 4 5 6 7 8
While intended for to be a challenge, since as it turns out the game was already pretty hard for them to grapple, I changed the prompt to simply list out where walls are placed in the format below, which at least helped agents to reason about where walls were placed (with varying levels of success in how the actually used this information).
- wall between (2, 1) and (2, 2)
- wall between (3, 1) and (3, 2)
...putting things together
Finally, with these things defined, it’s just a matter of whipping out a loop and calling each agent one at a time until one of them wins.
the results
Disclaimer
This doesn’t speak to the models’ absolute ability on playing Quoridor as with different designs and more helpful prompt engineering they could’ve fared better, but instead on how different models compared when presented with this (same) level of difficulty. My biggest interested was in comparing reasoning versus non-reasoning models.
Non-reasoning models suck at Quoridor. I was very surprised since I expected at least a decent showings by gpt-4o, and to be completely honest I had some faith on budget models like 4o-mini as well. Both their performances were so bad I didn’t even see a difference between the two of them.
lack of board understanding and real planning
These simpler non-reasoning models pretty much just wanted to move either up or down, straight at their objectives, pretty much regardless of what was going on. If they were in a situation where a wall or an enemy pawn was in their path, it was way more likely for them to attempt to move into them first, get the error, and then do something about it like sidestepping rather than getting it right the first time.
In some instances I’d even see them acknowledge in their planning that they wanted to move to square (r, c) while still mentioning that the enemy player was already on square (r, c). Still, they
attempt to do it and only afterwards say something like (verbatim) “The center square (4, 4) is
occupied by Player 0, so I cannot move DOWN to it.”
Further, they’d always end up just moving and never placing walls. While they sometimes included phrases like “I will start placing walls to hinder my opponent’s advance if they are nearing their objective.”, they’d still just move their pawn while the opposing player is a single move away from victory.
Upon not actually managing to “understand” what was happening, they just generated a bunch of plausible sounding tokens while moving almost aimlessly on the board.
modern non-reasoning models didn’t suck *as much*
It is worth noting that gpt-4.5 and claude-3.7-sonnet (non-thinking) did end up faring much better than these older models. They would ackowledge walls or players blocking their paths sometimes, and even place walls some of the turns (emergent behavior compared to older models). As a result, they were able to dominate older models.
I also need to disclaim that I only tested gpt-4.5 for 4 matches since it’s so darn expensive, costing ~60x as much as o3-mini and ~20x as much as Claude, so my conclusions on it could be the result of bad luck.
However, when facing reasoning models, their deficiencies showed, making it clear that (1) if there were a lot of walls they’d mostly wander around not finding a path stumbling into them, and (2) would fail to make good wall placements themselves, unable to really hinder the opponent and gain tempo.
o3-mini didn’t disappoint
I ran tests with o3-mini (on both medium and high efforts, without seeing a huge difference between the two) as well as Claude 3.7 Sonnet allowing for reasoning tokens.
In a few dozen matchups against non-reasoning models (including the standard variant of Claude) o3-mini only lost a couple times, both of which it hallucinated that the opponent was 2 steps away from their objective when they were really only 1 step away. Otherwise, it always understood the board, never running into walls or the player, it always placed walls aggressively and early to gain tempo against the opponent and generally understood the best path to victory.
It really represented what I expected from modern LLMs out of a game like Quoridor.
claude is king
Claude on the other hand was extremely satisfying to see play. While o3-mini dominated every other LLM I tested, it still didn’t seem to stand a chance against Claude 3.7 Thinking at all.
The first surprise from Claude is that it often included a step-by-step optimal path to victory for both itself and the opponent as part of its notes, which is probably what enabled it to plan ahead multi-turn wall placements to entrap the opponent.
Below is a snapshot of a match between o3-mini (Player 0, starting on the bottom) and Claude 3.7 Thinking (Player 1, starting on the top), where Claude planned ahead to put o3-mini in the following position, and even employing the use of vertical walls, the only model to do so.
+ + + + + + + + + +
8
+ + + + + + + + + +
7
+ + + + + + + + + +
6
+ + + + +---+---+ + + +
5 1 | 0 |
+ + + +---+---+ + + + +
4 | |
+ + + + + + + + + +
3
+ + + + + + + + + +
2
+ + + + + + + + + +
1
+ + + + + + + + + +
0
+ + + + + + + + + +
0 1 2 3 4 5 6 7 8The most impressive thing about the matches of Claude 3.7 Thinking versus o3-mini-high were that while it consistently would win, it wasn’t be because of obvious mistakes from the opponent, but instead on its own merit of actually thinking a few turns ahead. While o3-mini would always make valid and sensible moves, it was a too shallow and naive in terms of not seeing how Claude’s wall placements could easily mess up its plans.
It is about 3x more expensive than o3-mini and a newer model, but the dominance was still impressive to me.
what about gemini? and deepseek R1?
While I do use openrouter to test out competing models from different providers with the same API, not all models support the “tool call API” which I used to implement these moves for my own convenience (and I’m too lazy to go back and reimplement this to not use the feature).
This unfortunately means that I can’t use R1, since no providers support the tool call API. For Gemini 2.0 Flash Thiking, it’s just not enabled while it’s still in experimental release. Given how much cheaper (I expect) it will be compared to o3-mini, I’m looking forward to running that matchup once the model is fully out.
wrapping up
- gpt-4o-mini/gpt-4o 💩: performed equally bad, their plans just sounded like plausible english phrases with no actual meaning, they consistently made basic mistakes like walking into walls, barely ever placed walls themselves and just sucked overall and consistently lost to everything else
- gpt-4.5-preview 🫰: seemed to be considerably better than the older models (to my surprise), but it’s so much more expensive than anything else and still expetedly worse than reasoning models for this application, so I just didn’t bother testing it a lot
- Claude 3.7 Sonnet 👍: really a notch above other models (and appeared similar to 4.5, maybe slightly worse but at a huge discount), avoiding the most basic mistakes and sometimes placing walls, and while it dominated the simpler models, it showed its deficiencies when playing against reasoning models
- o3-mini 👏: dominated every non-thinking model, including Claude, never making basic mistakes, keeping good track of states and aggressively placing walls to gain tempo
- Claude 3.7 Sonnet (Thinking) 👑: dominated every other model I tested, managed to create
relatively complex traps against
o3-miniand even with a lot of walls placed it often kept the full expected path for itself and the opponent in its notes, allowing it to keep track of who’s winning and to place those traps in the first place
It was nice to see that the most recent non-reasoning models are better even at this type of task, but the thinking variants really clearly superior and dominated non-thinking models. I’m also really interested in testing Gemini 2.0 Flash Thinking once it’s out to see how it will fare given how much cheaper it will probably be compared to o3-mini.
If you want to run them yourself and perhaps even sink some dollars into making them fight repeatedly and create a table with nice statistics like ELOs, win-rates, etc. check out my code in my repo and feel free to hit me up!